'How to manage BigQuery tables post firestore backfill [google-bigquery]
I am interested in learning how to manage BigQuery post firestore backfills.
First off, I utilize the firebase/[email protected] function with a table named 'n'. After creating this table, 2 tables are generated n_raw_changelog, n_raw_latest.
Can I delete either of the tables, and why are the names generated automatically?
Then I ran a backfill, because the previous collection preceded the BigQuery table using:
npx @firebaseextensions/fs-bq-import-collection \
--non-interactive \
--project blah \
--source-collection-path users \
--dataset n_raw_latest \
--table-name-prefix pre \
--batch-size 300 \
-query-collection-group true
And now the script adds 2 more tables with added extensions
i.e. n_raw_latest_raw_latest, n_raw_latest_raw_changelog.
Am I supposed to send these records to the previous tables, and delete them post-backfill? Is there a pointer, did I use incorrect naming conventions?
Solution 1:[1]
As shown in this tutorial, those two tables are part of the dataset generated by the extension.
For example, suppose we have a collection in Firebase called orders, like this:

When we install the extension, in the configuration panel shows as follows:

Then,
As soon as we create the first document in the collection, the extension creates the
firebase_ordersdataset in BigQuery with two resources:
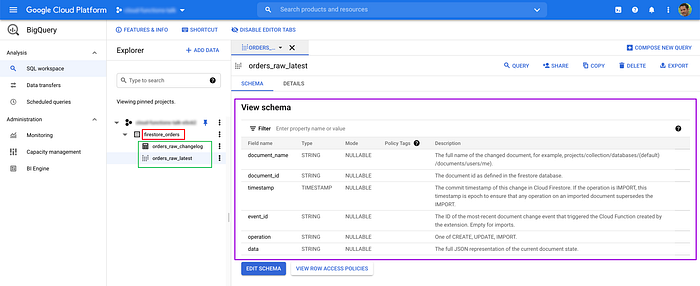
So, these are generated by the extension.
From the command you posten in your question, I see that you used the fs-bq-import-collection script with the --non-interactive flag, and pass the --dataset parameter with the
n_raw_latest value.
The --dataset parameter corresponds with the Dataset ID parameter that is shown in the configuration panel above. Therefore, you are creating a new dataset named n_raw_latest which will contain the n_raw_latest_raw_changelog table and the n_raw_latest_raw_latest view. In fact, you are creating a new dataset with your current registries, and not updating the dataset you created for instance.
To avoid this, as stated in the documentation, you must use the same Dataset ID that you set when configuring the extension:
${DATASET_ID}: the ID that you specified for your dataset during extension installation
See also:
Sources
This article follows the attribution requirements of Stack Overflow and is licensed under CC BY-SA 3.0.
Source: Stack Overflow
| Solution | Source |
|---|---|
| Solution 1 | Rogelio Monter |