'Destacking a table into variable columns (e.g. item1, item2, item3) such that the unique values in a column occupy those columns
This seems like it should be a simple problem, but I'm having trouble finding out how to do this for a non-numeric dataset where the number of columns to be created may be variable.
E.g. i want to split this:
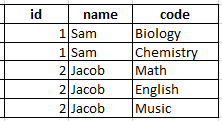
into this:

Where the number of columns added is variable (the whole dataframe's columns would be dynamically determined by whichever student had the most subjects).
The "id" and "name" columns go hand in hand.
Generating the dummy df:
pd.DataFrame({
'id':['1','1','2','2','2'],
'name': ['Sam','Sam','Jacob','Jacob','Jacob'],
'code': ['Biology','Chemistry','Math','English','Music']
}
)
Solution 1:[1]
You can define a subject-df and then join it to the grouped id and name columns:
df = pd.DataFrame({
'id':['1','1','2','2','2'],
'name': ['Sam','Sam','Jacob','Jacob','Jacob'],
'code': ['Biology','Chemistry','Math','English','Music']
}
)
df_subjects = pd.DataFrame(df.groupby(['id', 'name'])['code'].apply(list).to_list())
df_subjects.columns = [f'subject{i+1}' for i in range(len(df_subjects.columns))]
print(df.groupby(['id', 'name'], as_index=False).count()[['id', 'name']].join(df_subjects))
Output:
id name subject1 subject2 subject3
0 1 Sam Biology Chemistry None
1 2 Jacob Math English Music
Sources
This article follows the attribution requirements of Stack Overflow and is licensed under CC BY-SA 3.0.
Source: Stack Overflow
| Solution | Source |
|---|---|
| Solution 1 | Tranbi |